起因:最近想出一个高考志愿填报的excel系统,想先从网上拿一些资源,最开始的设计是希望从网站上找到近5年的报考指南PDF,然后写代码OCR扫描PDF,摘取关键数据,后发现网站没有PDF,于是告吹。后来就找寻网站,看看有没有我想要的数据,于是找到了”掌上高考“,发现有一些数据是想要的。(其实公司内有一个高考志愿网站,草率了)
处理数据:
第一步:打开开发者工具
找到对应的数据文件
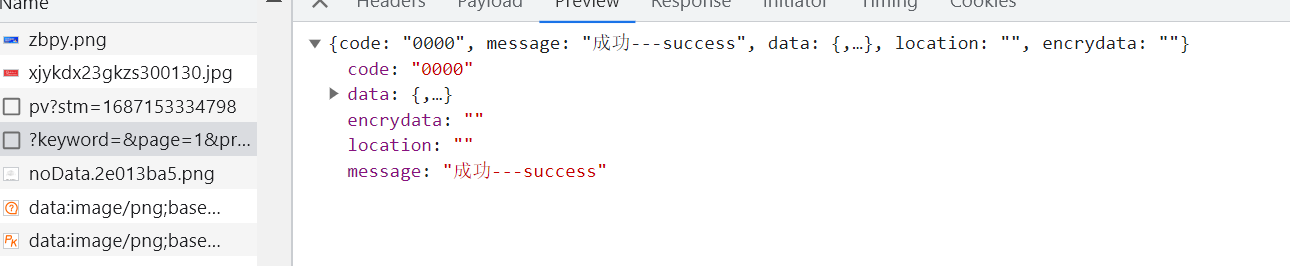
第二步:分析payload
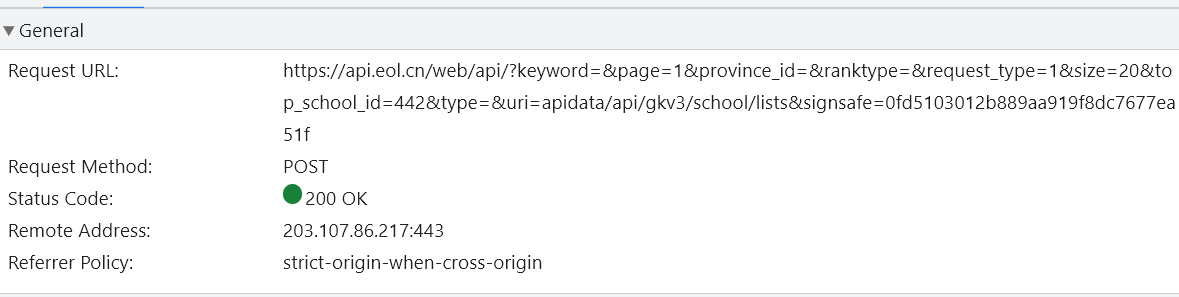
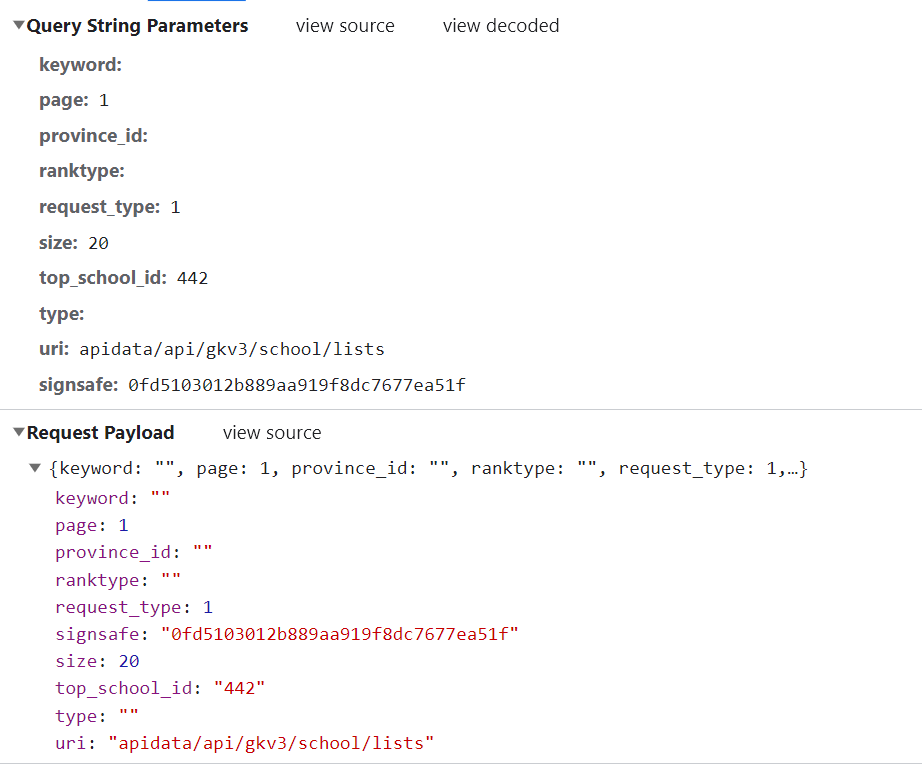
发现是一个POST请求,需要给他的服务器发送数据,再分析payload,发现里面有要发送的数据,里面有个signsafe(估计是个加密数据)看来必须要逆向才行了
后来发现这个网站做逆向纯属脱裤子放屁了。(既然可以用GET请求得到数据,signsafe就是个摆设)不过正好可以学习一下如何逆向。
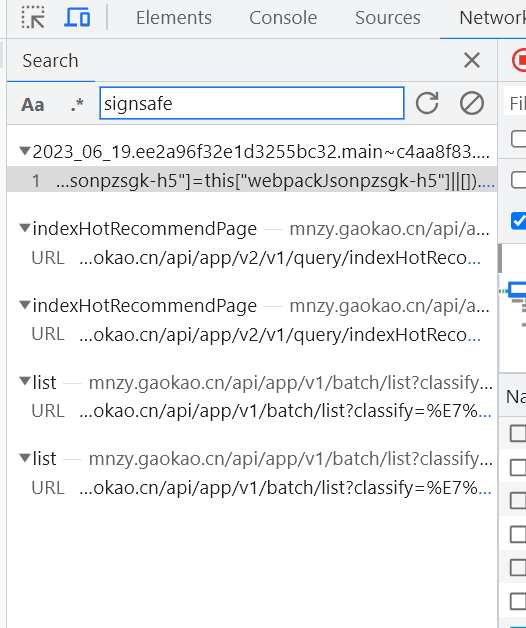
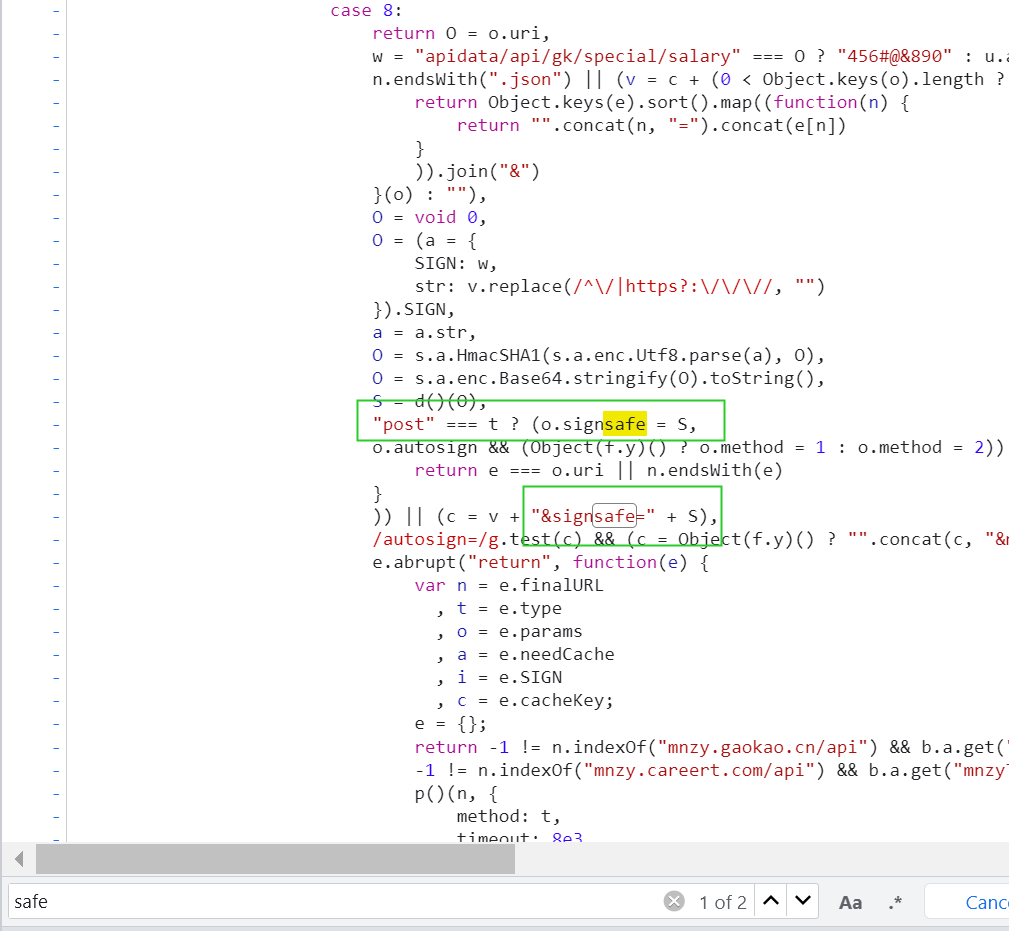
第三步:用search搜索一下signsafe(这个需要用H5模式)
发现了一堆数据,但是能用的就是第一个
第四步:分析数据
通过上下文判断是用的Hmac sha1加密,找到了signsafe
第五步:找到文件,用source打断点试试
根据文件夹的headers找到数据文件夹
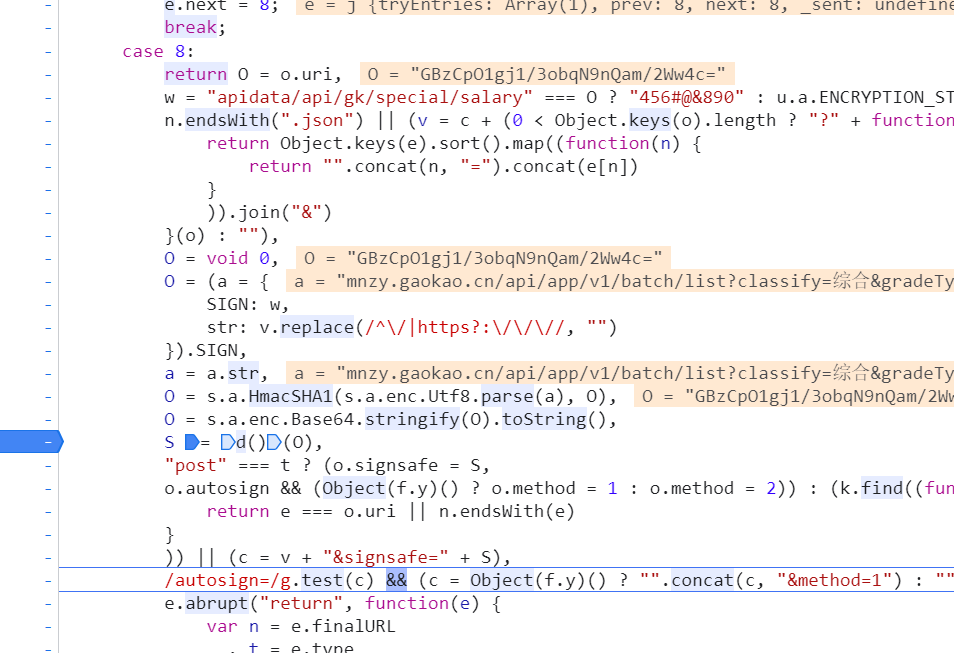
经过断点运行,多试了几次,发现就是这个代码。
这是一个加密的方法,所有的singsafe都走这一个方法,断点可以走第二遍,就能出现我们想要的safe
具体的加密逻辑是这样的:首先获取url(包括传递的数据),然后去掉https:\\,进行sha1加密,密钥是D23ABC@#56,加密后再进行Base64加密,再将加密的数据用MD5进行加密。最后进行拼接。
代码实现:
import requests
import hmac
import hashlib
import struct
import base64
import urllib
import common
import json
import time
from fake_useragent import UserAgent
# 将已知信息汇总
def StringConcatenation(url: str, p: int, n=None) ->str:
for i in range(p):
if 'signsafe' in common.data:
common.data.pop('signsafe')
if n == None:
common.data['page'] = i + 1
else:
common.data['page'] = i + n
# 将对象作为参数构建URL
# print(common.data['page'])
print('已完成:', i, '当前页数:', common.data['page'])
params = urllib.parse.urlencode(common.data)
params = urllib.parse.unquote(params)
url_new = url + '?' + params
# 构建加密信息
msg = url_new.replace('https://', '')
Encrypt(msg)
# 将信息加密
def Encrypt(msg):
# 基础信息
key = 'D23ABC@#56'.encode('utf-8')
msg = msg
# print(msg)
# hmac SHA1加密
h = hmac.new(key, msg.encode('utf-8'), hashlib.sha1).digest()
# base64 加密
b = base64.b64encode(h)
# md5 加密
m = hashlib.md5(b)
m = m.hexdigest()
print(m)
common.data['signsafe'] = m
# RequestsHttp()
# 做请求
def RequestsHttp(medth):
ua = UserAgent()
useragent = ua.random
common.headers['User-Agent'] = useragent
ips = proxies_ip()
proxies = {
'HTTP': ips,
'HTTPS': ips
}
print(ips)
if medth == 'post':
# 构建URL
res = requests.post(url=common.urls['url'], headers=common.headers,data=common.data)
res = res.content.decode('utf-8')
json_str = json.loads(res)
with open('school_all2.json3', 'a', encoding='utf-8' ) as f:
json.dump(json_str, f, ensure_ascii=False)
time.sleep(3)
else:
res = requests.get(url=common.urls['url'],headers=common.headers, proxies=proxies, verify=False)
res = res.content.decode('utf-8')
json_str = json.loads(res)
with open('spictial_school4.json', 'a', encoding='utf-8')as f:
json.dump(json_str, f, ensure_ascii=False)
# StringConcatenation(common.urls['url'])
def proxies_ip():
res = requests.get(url=url).text
# 判断高匿代理
url2 = 'http://example.com'
ips = res
print(ips)
proxies = {
'http': f'http://{ips}',
'https': f'https://{ips}'
}
try:
response = requests.get(url2, proxies=proxies, timeout=10)
if 'HTTP_X_FORWARDED_FOR' in response.headers:
print(f'Proxy {ips} 是高匿代理!')
print(ips)
else:
print(f'Proxy {ips} is not high anonymity.')
except:
print('出现异常')
return res
if __name__ == '__main__':
# common.urls['url'] = 'https://api.eol.cn/gh5/api'
# StringConcatenation(common.urls['url'], 10, 230)