一、背景:
今年3月份的时候做的一个工具项目,当时的背景是部门内每天会产出很多很多的垃圾文件,每天都是表格、ppt还有内容的产出,整合文件又需要一堆的表,沟通成本和文件产出成本居高不下。(职责所系,希望改变)
所以就想有一个工具可以将部门的沟通成本做下来,让产出垃圾的文件的时间变少,这样大家就有时间可以做价值产出的工作了,正好当时有一个dootask的开源项目,就想给部门做一个文件管理系统,在内网使用的,制作好上传的相关规则就可以了。(后来发现想太多了,想起来最近看的一个视频,苏联的科学家希望通过中央计算机来代替人,减除冗余机构和人数,除去无效劳作,最后导致机构冗余越来越大,纸张浪费也越来越大,工作效率反而更低下。还有个故事是说新来的人,在体制内做表,希望通过革新,用数据库做,表面看是效率是提升了,但是做了造成的问题反而更大,工作项更多,人更累,错误更多,反而得不偿失)
最后想说:除非有革命到底的念头,否则,能跑就别动。自古改革最难,比打烂了重新建更难。
得出的经验和教训:千万不要想着推翻重建,除非你是一把手,精英只能在顺应大多数人的基础上才能发挥作用,否则就是自讨没趣。
二、使用工具:
dootask:查看git安装步骤,用docker安装
mariadb数据库:数据库
三、项目需求:
- 插入硬盘就能识别
- 运行代码,将dootask存储的文件修改好名字,然后移动到指定的文件夹下
- 可以按照dootask文件存储的样式原封不动的移动过来,文件路径不能改变
- 最好是一套代码,可以远程直接操作
四、项目思考:
第一套方案:最初设想的是通过VBA 进行相关的操作,之前有过一个xlsm的文件管理系统,有导出,有修改名字。可以通过VBA进行实现,VBA远程连接mariadb数据库 ==> 通过sql语句导出相关内容 ==> 进行数据整合 ==> 获取移动硬盘的名称 ==> 然后再通过VBA进行文件迁移 ==> 最后修改文件名称。反正就是希望通过VBA来实现,只要在电脑上插上硬盘,然后打开VBA,按一次到两次按键就能操作完成。
(ps:后来放弃,可能是当时的技术水平有限,也可能是实现的时候发现有些什么问题处理不了,反正最后放弃了。好像是因为服务端用的是Ubuntu系统,office套件用的是libre office, 运行VBA可能更麻烦,放弃了。)
第二套方案:这套方案有点像缝合怪的意思,走一步看一步。通过python 和shell 进行实现。首先,远程通过运行python脚本本地连接mariadb数据库,然后将数据进行整合存入excel中, 接着,通过远程将这个excel表拉过来,将数据拆分进两个txt文本文件中,然后,将这两个txt文档通过远程放入ubuntu服务器中,紧接着插入硬盘,最后远程运行shell文件。
(ps:听着就很繁琐,而且跟之前想的大相径庭,现在做的话应该会简化一些,不确定)
五、遇到的卡点:
- 安装dootask,只能在Linux中安装,还有安装docker,在windows 中安装linux 系统,在自己的电脑上安装还行,就是hyper-v 的安装和启动,docker-compose安装。折腾了1个星期
- 然后在公司电脑上安装Linux老是报错,重新装了2次系统,最后实在是无奈,直接安装了ubuntu 系统,算是解决。折腾了半个月
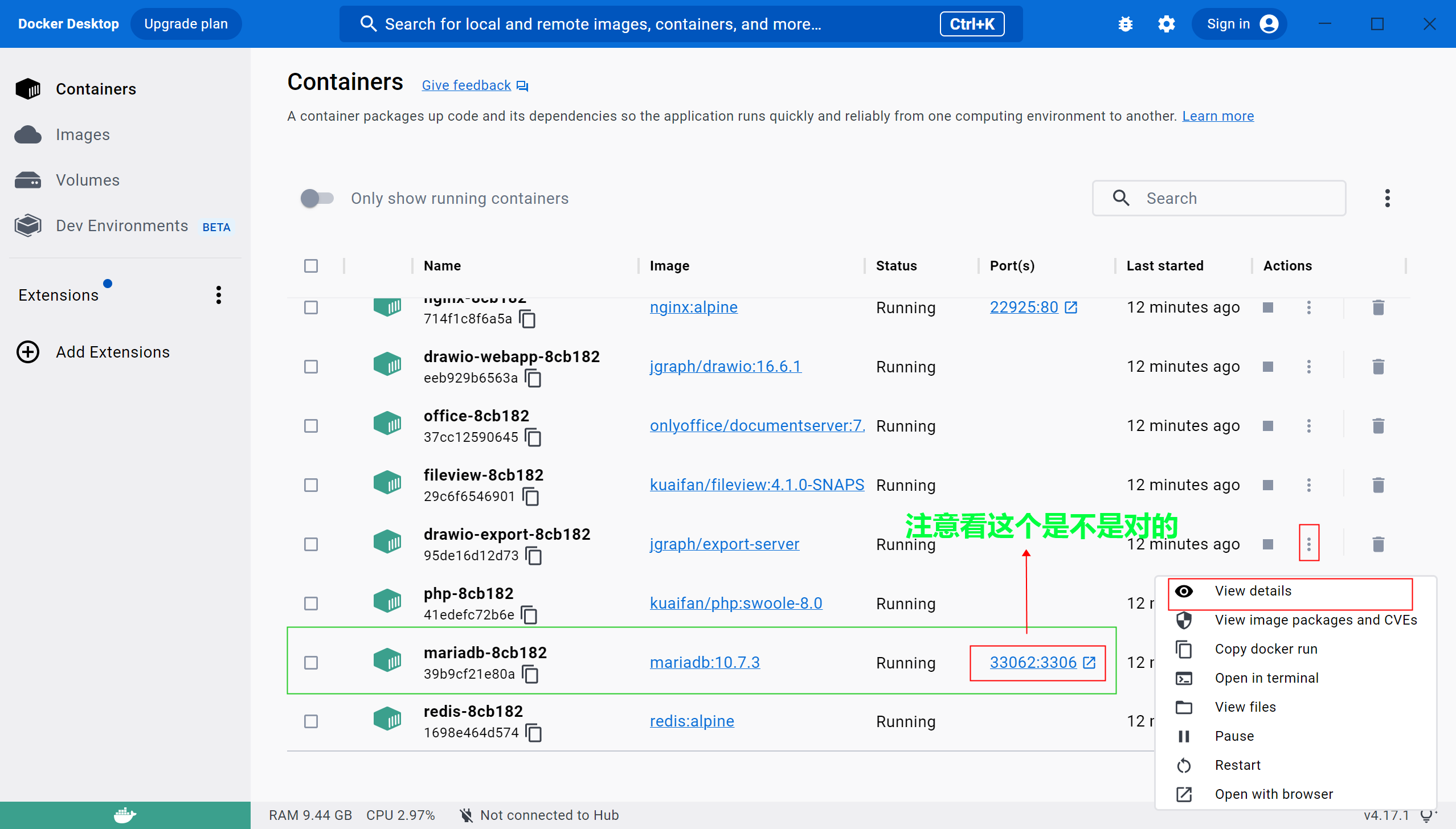
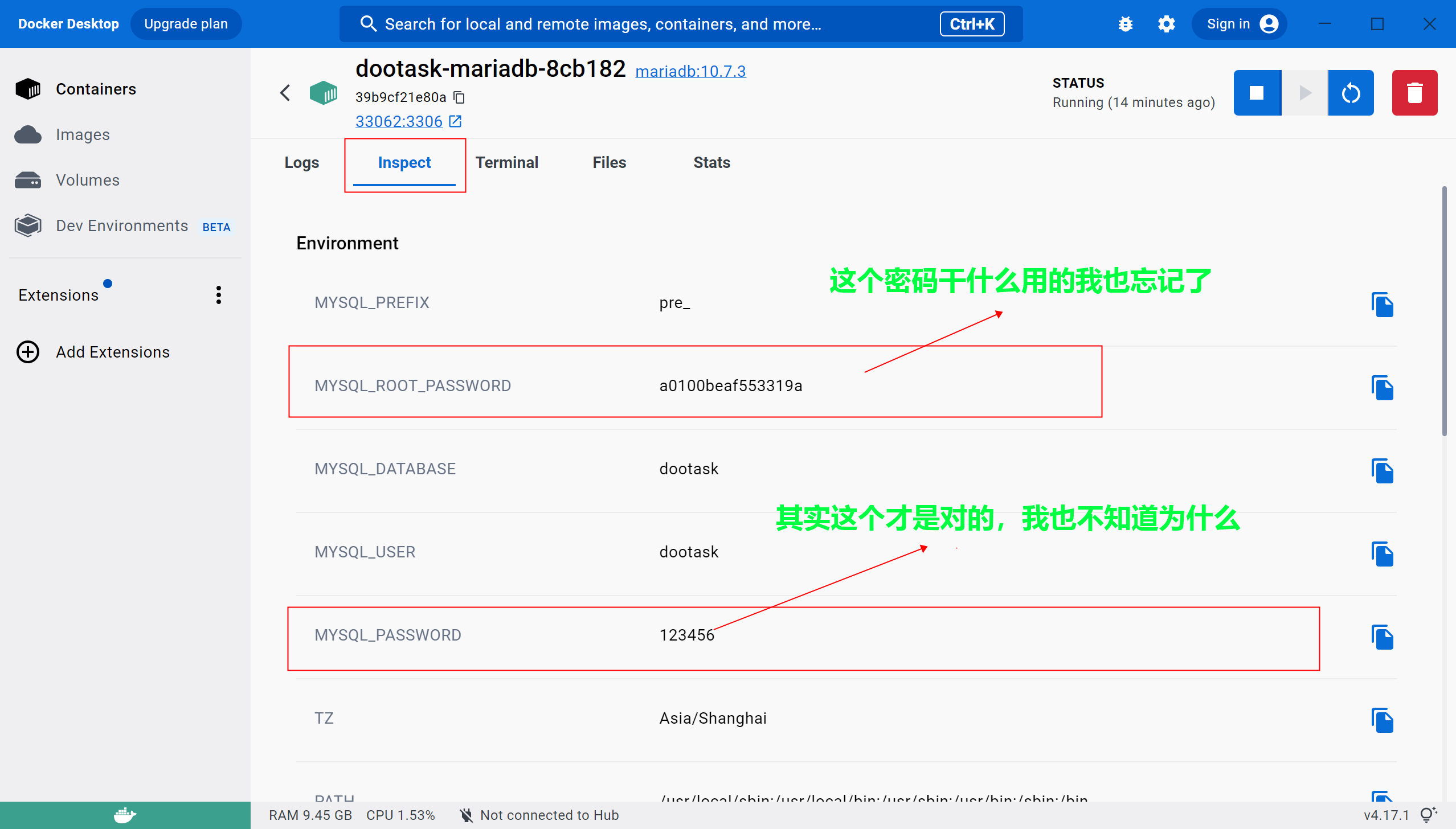
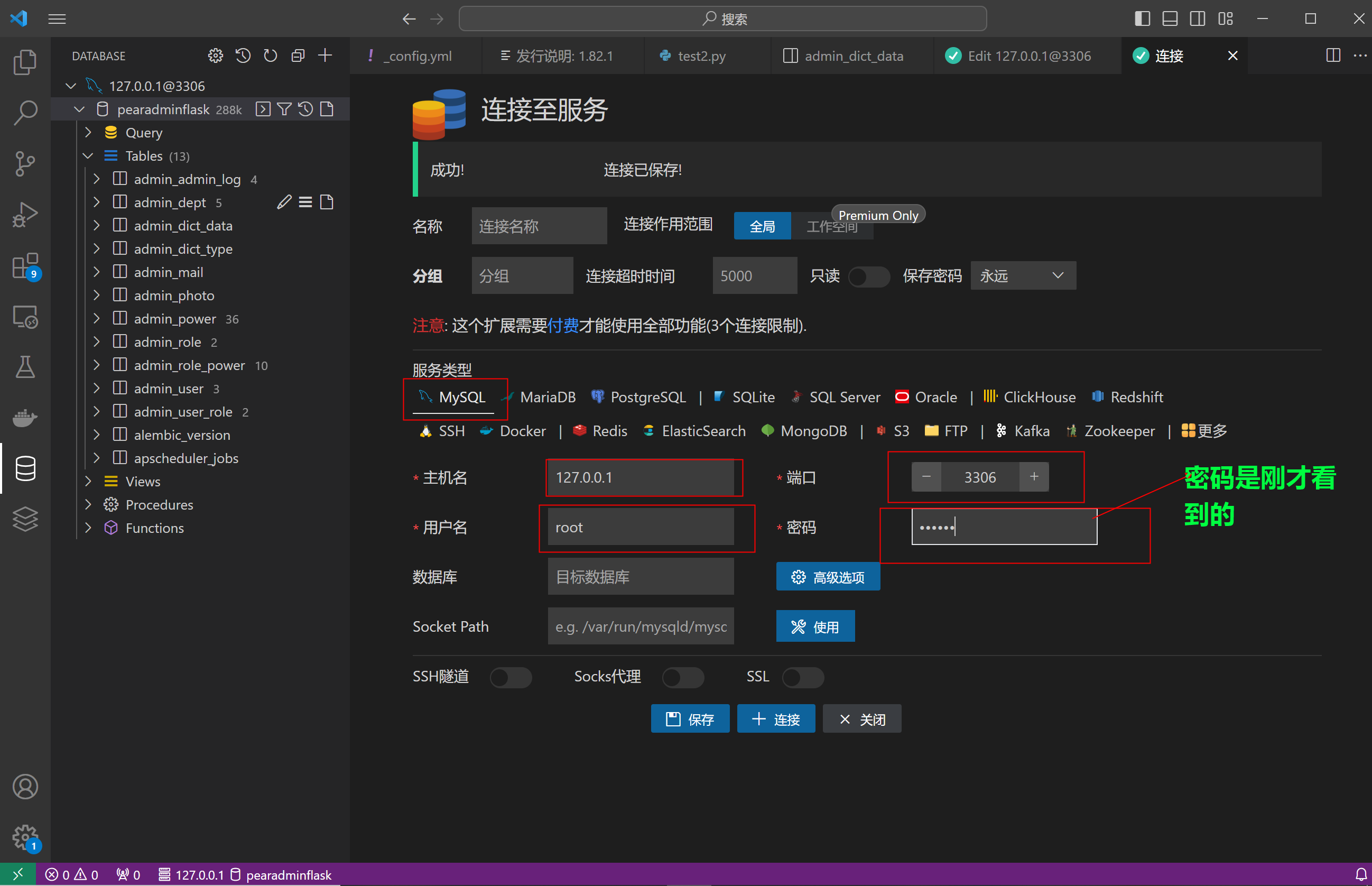
- 如何获取dootask 中mariadb 数据库的root名称和密码,并进行远程连接。基本上折腾了大半个月
- 如何安装网卡的问题,Ubuntu系统连接不上无线网,通过网卡不行,需要从git上安装驱动(放弃了,直接上网线)
六、具体实现
- 编写python 脚本
import mariadb
import xlsxwriter as xw
import json
import re
table = ['pre_files','pre_file_contents']
mariadbData = {
'database' : 'dootask',
'user': 'root',
'password': 'a0100beaf553319a',
'host': '127.0.0.1',
'port': '33062'
}
# print(mariadbData['database'])
# 判断存在的文件里最后的id值,返回一个true和数字
# 连接数据库
def connectSql(sql):
conn = mariadb.connect(user="root", password="a0100beaf553319a",
host="127.0.0.1", port=33062,
database="dootask")
cur = conn.cursor()
sql1 = sql
cur.execute(sql1)
result = cur.fetchall()
# print(result)
cur.close()
conn.close()
return result
# 数据拼接
new_urls = []
def montagDB():
sql = "SELECT content from pre_file_contents where deleted_at is NULL"
result = connectSql(sql)
old_url = [json.loads(url)['url'] for url in [old[0] for old in result]]
sql2 = "SELECT pids,name,ext FROM pre_files WHERE pre_files.id IN (SELECT fid FROM pre_file_contents WHERE deleted_at IS NULL)"
result2 = connectSql(sql2)
deal_db(result2)
# 获取文件名,获取上传人,获取上传日期
sql4 = "SELECT name,size,created_at,created_id FROM pre_files WHERE pre_files.id IN (SELECT fid FROM pre_file_contents WHERE deleted_at IS NULL)"
result4 = connectSql(sql4)
name, size, created_at, created_id = zip(*result4)
# sql5 = "SELECT nickname FROM pre_users WHERE pre_users.userid IN ( SELECT created_id FROM pre_files WHERE pre_files.id IN (SELECT fid FROM pre_file_contents WHERE deleted_at IS NULL))"
# result4 = connectSql(sql5)
print(name, size, created_at, created_id)
xw_toExcel(list(zip(name,size,created_at,created_id,old_url,new_urls)))
# 数据处理
def deal_db(arg):
if isinstance(arg, tuple):
if arg[0] == '':
new_urls.append(emplay(arg))
else:
new_urls.append(NotEmplay(arg))
else:
for fid in arg:
deal_db(fid)
# print(new_urls)
# 空
def emplay(fid):
# if not isinstance(arg, list):
arg = list(fid)
new_path = '/'.join(fid)
new_path = re.sub(r'/([^/]+)$', r'.\1', new_path)
return new_path
# 非空
def NotEmplay(fid):
fid = list(fid)
ids = fid[0].split(',')
i = 0
for id in ids:
if id:
sql3 = "SELECT NAME FROM pre_files WHERE id =" + id
file_name = connectSql(sql3)[0][0]
ids[i] = file_name
i+=1
fid[0] = emplay(ids)
new_path = fid[0] + fid[1] + '.' + fid[2]
return new_path
title = ['文件名','大小','创建时间','上传人','邮箱','旧地址','新地址']
# 写入数据表
def xw_toExcel(result):
workbook = xw.Workbook('test.xlsx')
workbookSheet1 = workbook.add_worksheet()
for i in range(len(result)):
for j in range(len(result[i])):
workbookSheet1.write(i, j, result[i][j])
workbook.close()
if __name__ == '__main__':
montagDB()- 编写shell脚本
#!/bin/bash
# 操作明细(source_file.txt 放源文件地址,dist_file.txt 放目标文件地址)
# 获取移动硬盘地址是自动获取的,如果需要修改联系管理员
# 将文件放入制定文件夹下
# 设置源文件夹地址和目标文件夹地址
# 获取插入的移动硬盘盘符
disk_name(){
# 检测是否找到块设备
mount_point=$(df -h | grep 'media' | awk '{print $6}')
if [[ ! -z $mount_point ]]; then
echo "移动设备盘符为 $mount_point"
root_src="/home/liuli/公共的/dootask/public"
dest_folder "$mount_point" "$root_src"
else
echo "未找到"
fi
}
#dos2unix 是将 Windows 格式文件转换为 Unix、Linux 格式的实用命令。Windows 格式文件的换行符为\r\n ,而Unix&Linux 文件的换行符为\n.dos2unix 命令其实就是将文件中的\r\n 转换为\n。
dest_folder(){
dev=$1
root_dev=$2
dos2unix /home/liuli/公共的/source_file.txt
dos2unix /home/liuli/公共的/dest_file.txt
source_folder=$(cat /home/liuli/公共的/source_file.txt)
source_list=(${source_folder[@]})
echo "${source_list[2]}"
i=0
while read line; do
source_folders=${source_list[$i]}
file_path=$(dirname -- "$line")
file_name=$(basename -- "$line")
#echo "$file_name"
echo "$1/$file_path/$file_name"
if [ -e "$1/$line" ]; then
echo "$file_name 文件已存在"
else
echo "正在创建"
sudo mkdir -p "$1/$file_path"
sudo cp -r "$2/$source_folders" "$1/$file_path/$file_name"
echo "$file_name" "已经复制完毕"
$(i+=1)
fi
done < /home/liuli/公共的/dest_file.txt
}
disk_name- 远程连接
# 要通过SSH将文件传输到Ubuntu电脑中,您可以使用scp命令。以下是一些基本的scp命令语法,可帮助您完成文件传输过程:
#将文件从Windows传输到Ubuntu:
scp /path/to/local/file user@ubuntu:/path/to/destination/directory
# 将文件从Ubuntu传输到Windows:
scp user@ubuntu:/path/to/remote/file /path/to/destination/directory
# 其中,/path/to/local/file是本地Windows环境中的文件路径,user是Ubuntu电脑的用户名,ubuntu是Ubuntu电脑的IP地址或主机名,/path/to/destination/directory是Ubuntu电脑中存放文件的目录路径,/path/to/remote/file是Ubuntu电脑中要传输的文件路径,/path/to/destination/directory是本地Windows环境中存放文件的目录路径。
# 在使用scp命令之前,确保您的Windows电脑和Ubuntu电脑已经通过SSH连接成功。
ssh 192.168.84.143@liuli
scp liuli@192.168.84.143:/home/liuli/公共的/pymariadb/test.xlsx /D:/ceshi/sshtcp
scp D:/ceshi/sshtcp/*.txt liuli@192.168.84.143:/home/liuli/公共的七、文章参考:
windows 安装Docker步骤以及在每一个步骤遇到问题合集
八、实现中的细节点
- dootask 中数据库的位置及查看方法